안녕하세요. TAK 입니다:)
지난 1부에 이어서 2부 "Grafana 대시보드화 구성과 AlertManager 를 통한 알림 서비스 연동" 으로 돌아왔습니다!
1부와 이어지는 내용이기에 아래 링크를 통해서 확인 후에, 이번 포스팅을 팔로우 하시면 이해하는 데 편하실거에요:)
1부 : Prometheus(+ Node Exporter, AlertManager) + Grafana 구성하기
안녕하세요. TAK 입니다:) 요번 Monitoring & Alert 를 위해 많이 사용되는 "Prometheus(+ Node Exporter) + Grafana" 주제를 준비했습니다! (별도의 Category 를 만들까 했지만, 제가 처음으로 포스팅한 내용처럼 조
with-cloud.tistory.com

그럼 시작하겠습니다!
Contents
2-1. Grafana 구성
2-1-1. Grafana 설치
구성도에서 처럼 Promethues Server가 아닌, 별도의 Grafana Server(Ubuntu 22.04)에서 구성하겠습니다.
자세한 사항은 Offical Docs 를 참고해 주세요!
(가이드 등 세부 내역이 상세히 잘 되어 있는 느낌..!)
Download Grafana | Grafana Labs
Overview of how to download and install different versions of Grafana on different operating systems.
grafana.com
- Grafana Packages Repository 추가
sudo apt-get install -y apt-transport-https software-properties-common wget# GPG key
sudo mkdir -p /etc/apt/keyrings/
wget -q -O - https://apt.grafana.com/gpg.key | gpg --dearmor | sudo tee /etc/apt/keyrings/grafana.gpg > /dev/null# To add a repository for stable releases
echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list# Updates the list of available packages
sudo apt-get update
# Installs the latest OSS release:
sudo apt-get install grafana
- Systemd Service 시작
sudo systemctl daemon-reloadsudo systemctl enable grafana-server.service
sudo systemctl start grafana-server.service
sudo systemctl status grafana-server.service
- NSG 확인
- Azure Ubuntu의 경우, 방화벽의 Default 값은 Inactive 이므로, NSG(Netwokr Security Group)에서 제어합니다.
- Grafana의 Default Port : 3000

2-1-2. Grafana 설정
- 액세스 확인 및 초기 Login 정보
- 초기 Login 정보 > ID : admin / PW : admin
- 최초 접속 이후에, PW 변경 지시에 따라 변경 권장

- Data Source 설정하기
- 실제 시각화할 데이터의 원본을 설정하는 단계입니다.

- Prometheus Server 추가


- Promethues Server의 URL 추가
- 연결을 위한 아래 빨간 네모 박스 설정 이외에 인증, 보안 등 여러 설정이 있지만, 해당 과정에서는 Defualt 값으로 진행합니다.
- 또한, UI 상에서 Prometheus, Grafana 사용을 위해 VM의 연결된 Public IP를 사용했지만, 모든 연결 설정은 Private IP 사용합니다.

→ 빨간 네모 박스 안, Prometheus Server URL의 경우
1부에서 구성한 /etc/prometheus/prometheus.yml 파일의 "localhost:9090" 입니다.
다만, 위 값에는 VM에 할당된 Private IP를 기입하여 "http://<Private IP>:9090" 입력합니다.
(여기서, Priavte 환경에서는 VM의 Private IP를 적지만, 우선 Public IP도 함께 사용 중이므로 localhost 값을 유지하였습니다.)

- 연결 확인


2-2. Grafana 대시보드


2-2-1. Self 테스트 구성
- 초기 빈(Empty) 구성의 Custom Panel 생성
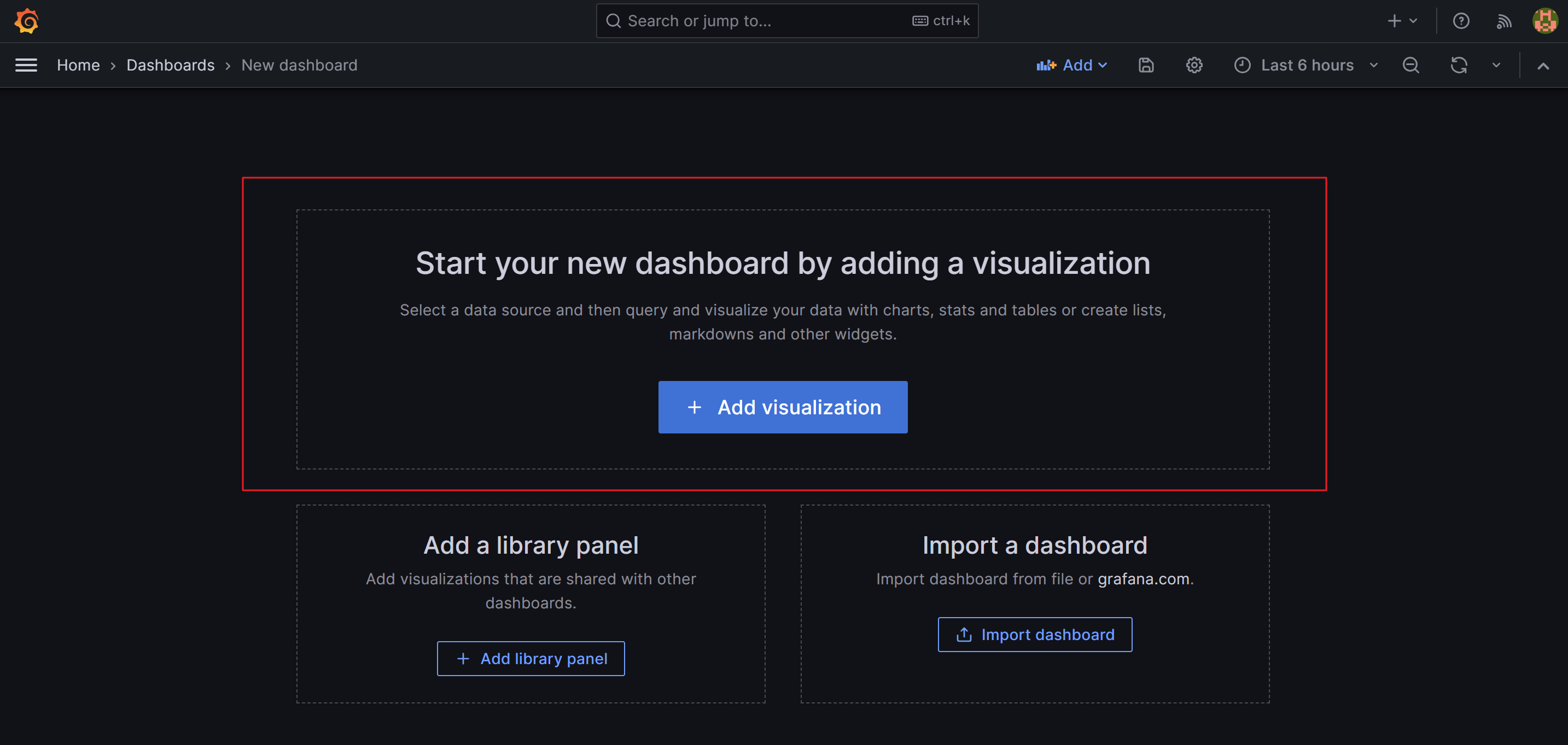

- 대시보드를 위한 구성
- 1,2번 항목 : 대시보드화할 Metics 종류와 Filter 선택
- 3번 항목 : 1,2번 항목에서 선택 값이 구체화되는지 확인
- 4번 항목 : 대시보드에 해당 값을 저장



- 대시보드 확인
- 위 단계를 반복하며 원하는 Metrics과 Filter 선택하여 목적에 맞게 대시보드 구성


- 구성 대시보드 저장



2-2-2. Template 사용 구성
Grafana 에서 제공하는(타 사용자들이 공유) Template을 활용한 대시보드를 구성합니다.
- Import


- 대시보드 적용 Sample 확인
- 아래 사이트에서 대시보드에 적용할 샘플을 업로드합니다.
- 해당과정에서는 Copy ID (URL 혹은 ID) 방식을 사용합니다.
Dashboards | Grafana Labs
Thank you! Your message has been received!
grafana.com
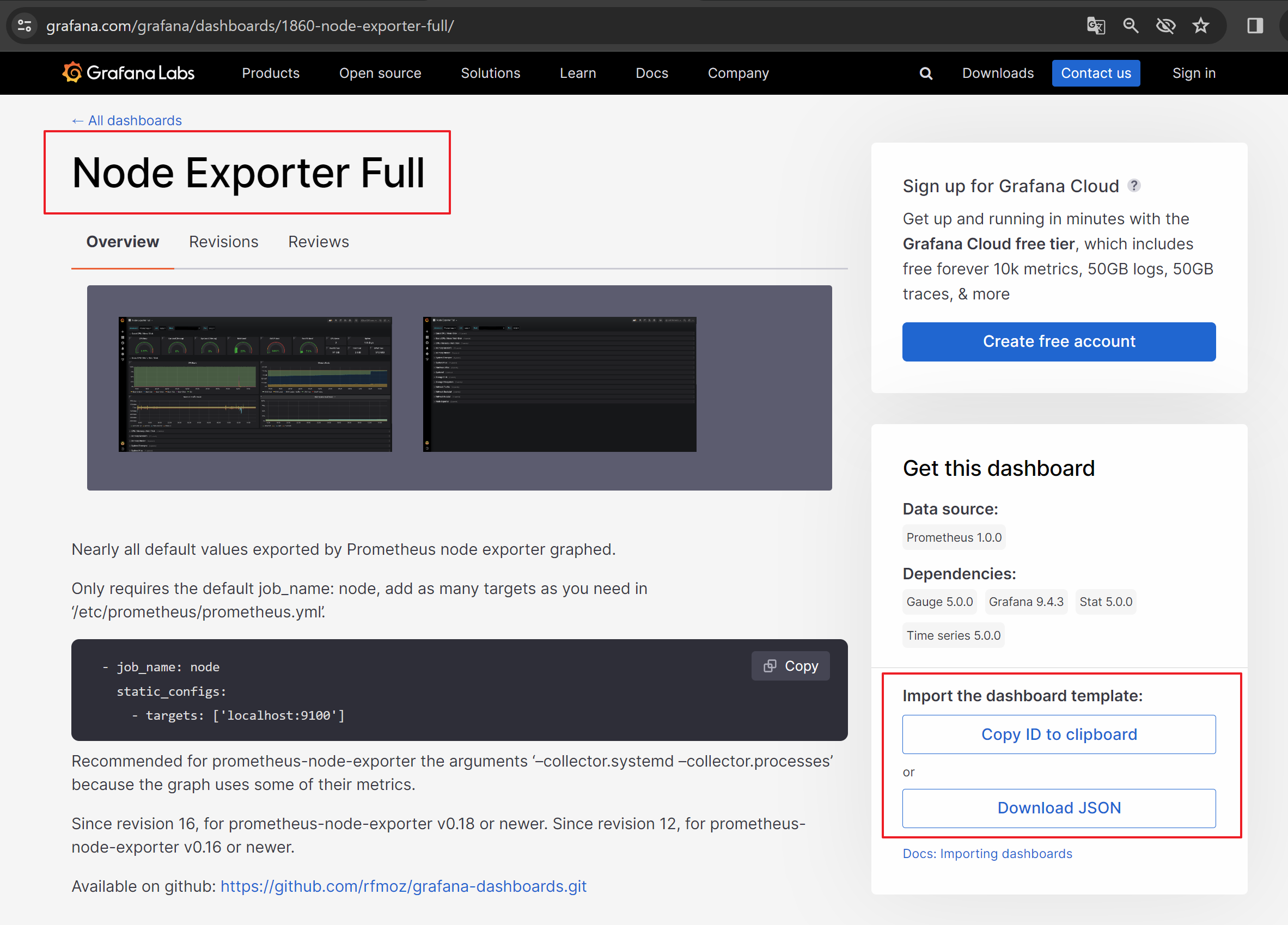
- Copy ID 적용 후, Import dashboard를 위한 Options 설정

2-3. 멋진 최종 DashBoard 확인
- Import 기능을 사용하여 제공되는 여러 Template을 기반으로 일반적인 Metrics 활용한 멋진 대시보드 완성!
- 제공되는 여러 옵션을 선택하여 다양한 시각화를 제공합니다.

2-4. Alertmanager 구성
2-4-1. Alertmanager 설치
Alermanager도 위 단계에서 사용한 Grafana VM에서 설치하여 사용합니다.
- Binary 파일 다운로드
Download | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
wget https://github.com/prometheus/alertmanager/releases/download/v0.26.0/alertmanager-0.26.0.linux-amd64.tar.gz - Alermanager 시스템 그룹 및 사용자 할당(+ 디렉터리 생성)
sudo groupadd --system alertmanager
sudo useradd -s /sbin/nologin --system -g alertmanager alertmanager
sudo mkdir -p /etc/alertmanager/templates
sudo mkdir /var/lib/alertmanager
sudo chown alertmanager:alertmanager /etc/alertmanager
sudo chown alertmanager:alertmanager /var/lib/alertmanager
- 압축 풀고, 디렉터리 이동
tar -xvf alertmanager-0.26.0.linux-amd64.tar.gz
cd alertmanager-0.26.0.linux-amd64.tar.gz

- Binary 파일 (로컬) 이동 및 소유자 설정
sudo mv alertmanager /usr/local/bin
sudo mv amtool /usr/local/bin
sudo chown alertmanager:alertmanager /usr/local/bin/alertmanager
sudo chown alertmanager:alertmanager /usr/local/bin/amtool

- 구성 파일 이동 및 소유자 변경
sudo mv alertmanager.yml /etc/alertmanager/alertmanager.yml
sudo chown alertmanager:alertmanager /etc/alertmanager/alertmanager.yml

- Alertmanager Systemd Service 만들기
sudo nano /etc/systemd/system/alertmanager.service
[Unit]
Description=AlertManager
Wants=network-online.target
After=network-online.target
[Service]
User=alertmanager
Group=alertmanager
Type=simple
ExecStart=/usr/local/bin/alertmanager \
--config.file /etc/alertmanager/alertmanager.yml \
--storage.path /var/lib/alertmanager/ \
--cluster.advertise-address="<Private IP>:9093"
[Install]
WantedBy=multi-user.target

** (Alertmanager의 HA mode) The cluster.advertise-address flag is required if the instance doesn't have an IP address that is part of RFC 6890 with a default route.

GitHub - prometheus/alertmanager: Prometheus Alertmanager
Prometheus Alertmanager. Contribute to prometheus/alertmanager development by creating an account on GitHub.
github.com
- 구성 사항 반영을 위해 Reload Systemd
sudo systemctl daemon-reload
2-4-2. Alertmanager Service 시작
sudo systemctl enable alertmanager
sudo systemctl start alertmanagersudo systemctl status alertmanager

- 방화벽 허용(Azure NSG 허용 정책)
- Azure의 VM의 경우, 방화벽 설정이 Default 값으로 Inactive(비활성화) 입니다.
- 따라서, 해당 과정에서는 NSG 정책으로 In/Out Bound 제어합니다.
- InBound 정책 추가 : Default Port 9093

- Prometheus 정상 액세스 확인
- 내부 확인 : curl -X GET http://localhost:9093

2-4-3. Prometheus Server연동
다음과 같은 목적을 기반으로 작업 수행을 위해 Prometheus Server를 구성합니다.
- Prometheus Server에서 Sraping 한 메트릭 데이터를 기반으로 Alertmanager에서 Alert을 보낼 수 있도록
- Grafana에서 Alertmanager에 대한 영역을 모니터링할 수 있도록
- Config 변경(추가)
- Alertmanager를 Grafana VM에서 구성했기에, 해당 VM의 <Private IP>:9093 를 Target으로 입력합니다.
- 별도의 NSG 정책을 추가하지 않는다면, Azure에서는 기본 정책으로 VNET 내 Private IP 기반 통신의 경우, Source/Destination 및 Port의 제한이 없습니다.
sudo nano /etc/prometheus/prometheus.yaml
- 서비스 재시작하여 변경값 적용
sudo systemctl restart prometheus
- Prometheus Target 정상 UP 확인
- 위 Config 값에 구성한 값이 정상 반영된 것을 확인할 수 있습니다.

2-5. Alertmanager 경고 규칙 만들기
Prometheus Server 에서 정의한 경고 규칙에 따라, Alertmanager 가 정해진 구성값(ex. Slack, Email)을 기반으로 알림(Alert)를 보내기 위한 단계입니다.
- Prometheus Server 에서 Rule 생성
- 규칙의 경우, Sample 제공하는 사이트의 자료를 참고하였습니다.
- 총 5개의 규칙을 위한 조건을 정의하였습니다.
- InstanceDown
- HostHighCpuLoad
- HostOutOfMemory
- HostMemoryUnderMemoryPressure
- HostOutOfDiskSpace
sudo nano/etc/prometheus/alert_rules.yml
groups:
- name: alert_rules
rules:
# instance(Host VM) is down on {{ $labels.instance }}
- alert: InstanceDown
expr: up == 0
for: 0m
labels:
severity: "critical"
annotations:
summary: "Endpoint {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
# CPU load is > 80%
- alert: HostHighCpuLoad
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 80
for: 0m
labels:
severity: warning
annotations:
summary: "Host high CPU load (instance {{ $labels.instance }})"
description: "CPU load is > 80%\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
# Node memory is filling up (< 10% left)
- alert: HostOutOfMemory
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10
for: 2m
labels:
severity: warning
annotations:
summary: "Host out of memory (instance {{ $labels.instance }})"
description: "Node memory is filling up (< 10% left)\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
#The node is under heavy memory pressure. High rate of major page faults
- alert: HostMemoryUnderMemoryPressure
expr: rate(node_vmstat_pgmajfault[1m]) > 1000
for: 2m
labels:
severity: warning
annotations:
summary: "Host memory under memory pressure (instance {{ $labels.instance }})"
description: "The node is under heavy memory pressure. High rate of major page faults\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
# Disk is almost full (< 10% left)
- alert: HostOutOfDiskSpace
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: warning
annotations:
summary: "Host out of disk space (instance {{ $labels.instance }})"
description: "Disk is almost full (< 10% left)\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- Rules 적용
- 위 작성한 Rule에 대한 스크립트를 Promethues Config에 반영합니다.
sudo /ect/prometheus/prometheus.yml
- Prometheus Server 서비스 재기동
sudo systemctl restart prometheus.services
- Rules 반영 확인
- Prometheus Server 접속 > Status > Rules

- Prometheus Server > Alerts

- Prometheus Server 접속 > Status > Rules
2-6. Alertmanager 통한 Slack 알림 보내기
자, 이제 마지막 단계입니다.
최종적으로 수집된 메트릭 데이터를 기반으로 규칙을 반영하여 Slack에 알림 보내겠습니다!
(메일 알림의 경우, 타 자료가 많은 관계로 생략하였습니다_._)
- Alermanager Config 설정
- slack_api_url의 값에 Slack에서 생성한 Incoming Webhook 앱의 URL 값을 입력합니다.
(이번 포스팅에서는 발급 과정에 대해서는 생략합니다.) - 보다 자세한 사항(옵션값의 대한 정의 등)은 공식 Docs를 참조
Configuration | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
- slack_api_url의 값에 Slack에서 생성한 Incoming Webhook 앱의 URL 값을 입력합니다.

- 실제 알림을 위해 Node 중 1대의 VM을 OFF
- Alertmanager 확인(InstanceDown)

- Premetheus 확인

- Slack 알림 확인

- Alertmanager 확인(InstanceDown)
지금까지 2부 "Grafana 대시보드화 구성과 AlertManager 를 통한 알림 서비스 연동" 알아보았습니다.
이것으로 1,2부 동안 진행한 "Prometheus(+ Node Exporter, AlertManager) + Grafana 구성" 포스팅을 마치겠습니다.
궁금한 점이나 이번 포스팅에서 부족한 점 등 자유로운 의견을 남겨주세요!
(!많관부!) 다음에도 함께 공유할 수 있는 주제를 가지고 찾아뵙겠습니다. (!많관부!)
'TOPIC > Data' 카테고리의 다른 글
| Streamlit으로 웹 애플리케이션 만들어보기 (0) | 2024.04.19 |
|---|---|
| Streamlit이란? (0) | 2024.04.17 |
| 1부 : Prometheus(+ Node Exporter, AlertManager) + Grafana 구성하기 (0) | 2024.02.15 |
| 데이터(Data)와 로그(Log) (1) | 2023.11.24 |